linux 工作中常用的性能检查 - 结果导出 - 文本处理
emmm。。。我这 18 线城市的运维,经常得对服务器进行性能检查,并把结果进行导出。大多数时候服务器都是没啥问题的,所以时间都费在复制粘贴上了,如果把那些持续运行的命令结果直接导出,然后全部合并在一起以格式化输出不就省事了?
cpu 性能检查——top 与 ps 之争!
top 可以看 cpu 占用率这个大家应该都知道。但 ps 其实也可以看。因为当我们运行 ps aux 的时候:
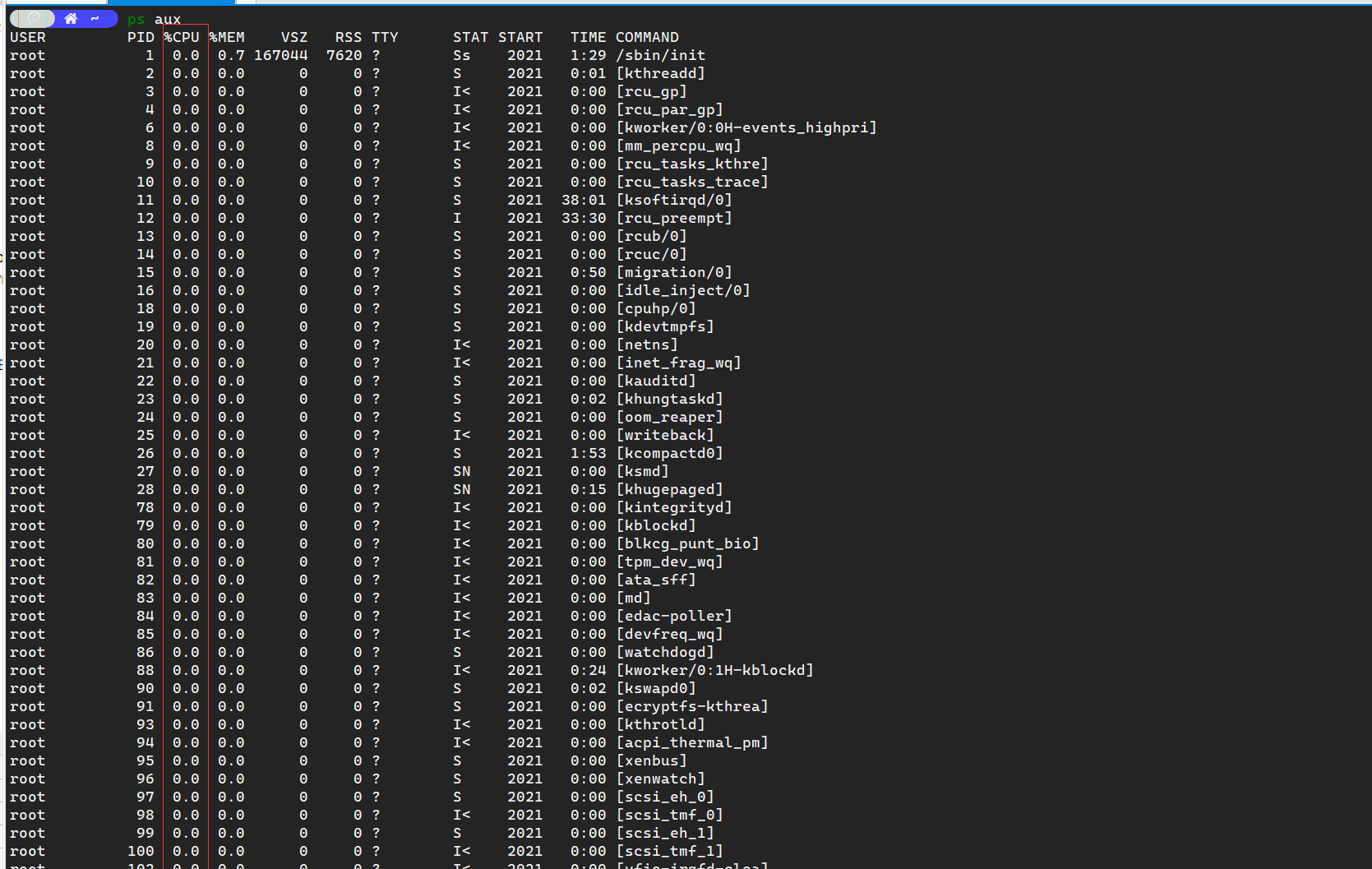
这一排 cpu 占用率实际上是可以利用起来的:
1 | ps aux|sed 1d|awk '{a+=$3}END{print a"%"}' |
这一行命令下去,就可以直接得出当时的 cpu 占用率了,相比从茫茫的 top 运行屏幕中把结果摘出来,是不是方便了不少?
且慢!
实际上,当你用多了这个命令,不难发现几个奇怪的地方:
- 当负载起来以后,如果恰好你的机器是多核心的话。。。就会发现,出来的数字怎么就大于 100% 了呢?
- 负载下去以后,发现出来的数字并没有马上降下去,但是多敲几次命令的话,会发现越到后面数字越低,但很长一段时间都不会是低负载时的哪个占用率,奇怪,此时 cpu 占用率应该已经接近 0 了呀?
- 发现 root 下运行出来的结果和非 root 下运行的结果居然差了 10 个百分点?
实际上,这几个问题的答案,就能充分反映出 ps 和 top 两个命令之间的机制差异:
top 的 cpu 最大值是 100,而 ps 统计出来的 cpu 最大值上限是 100xCPU 核心总数的值。假设一台机器有两个 cpu,每个 cpu 有四个核心,那么
ps aux统计出的 cpu 最大值上限就是 100*2*4=800;参考linux - ps and top give different CPU usage - Super User
from man top:
- %CPU – CPU Usage The task’s share of the elapsed CPU time since the last screen update, expressed as a percentage of total CPU time.
from man ps:
CPU usage is currently expressed as the percentage of time spent running during the entire lifetime of a process.
翻译成人话就是:top 的结果更即时,严格反映出当前时间点的 cpu 占用;而 ps 中进程的 cpu 占用率是当前进程全生命时间占用率的平均值。
在非 root 账户下 ps 输出的结果不包含 root 状态下运行进程的 cpu 占用。
所以嘛,平时对服务器的检查究竟用哪个比较合适呢?
思来想去,我觉得其实都可以。虽然 ps 不包含 root 下的进程,但企业用的服务器为了安全着想,本就不会在 root 下运行高占用的进程;而平时 cpu 占用率检查的意义,一个是查看当前时间点的 cpu 占用率是否过高(突发负载),更重要的目的,或许还是判断当前 cpu 是否能胜任所负担的工作(平均负载)。这么说,两个命令应该配合着使用才对呀,不过,检查要填的单子里面只用填一个 cpu 占用率数据,所以嘛。。。
对于 ps,只要把上面的命令处理一下,除一下核心数就好了:
1 | ps aux|sed 1d|awk -v cpu=$(cat /proc/cpuinfo| grep "processor"| wc -l) '{a+=$3/cpu}END{print a"%"}' |
对于 top,也可以通过 -n1 只运行 1s,然后通过 sed 和 awk 摘出里面的 cpu 占用数据:
1 | top -n1|sed -n '3p'|awk '{print $2}' |
拼接结果:大显神通的 paste 和拦路虎 ansi 字符
几个命令之间当然也可以通过 && 来拼接起来,只不过输出不在同一行;而用 paste 的话,不仅输出在同一行,而且命令与命令之间的输出中间会自动插入一个制表符,粘贴到表格里面刚好就会变成两格,简直就是懒人的福音!
但是嘛。。。我这边还有一个需求,那就是把 top 第一行后面这些带时间的内容输出出来,也就是这串:
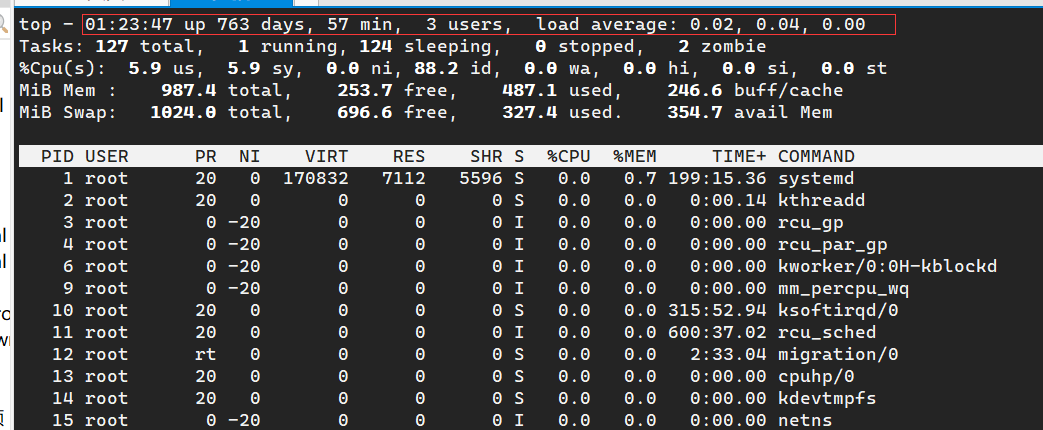
按理来说,配合 sed 就可以了,顺便剪掉前面的 top:
1 | top -n1|sed -n '1p'|sed 's/top - //g' |
然后我发现,运行完以后会莫名其妙的做一次清屏。这样复制粘贴就不方便了。
原因也挺简单的。里面混有 ansi 字符,输出出来:
1 | top -n1|sed -n '1p'|sed 's/top - //g' > ansi.txt |
用 vim 看一眼:

拖下来再用 vscode 看一眼:

好家伙显示出来的效果都不同。。。
不过原理都差不多,vscode 这里的 ESC 就等效于上面 vim 的 ^[,同时还等效于\x1B。但使用 sed 命令去处理的话,只有 \x1B 能成功匹配到这些个 ensi 符号。所以我们可以先把这些符号给转成可见性比较好的英文字符,参考:用 sed 去除文件中的 ASCII 控制字符乱码_Fu_Tianshu的博客-CSDN博客
1 | top -n1|sed -n '1p'|sed 's/top - //g'|sed -r -e 's/\x00/[NUL]/g' -e 's/\x01/[SOH]/g' -e 's/\x02/[STX]/g' -e 's/\x03/[ETX]/g' -e 's/\x04/[EOT]/g' -e 's/\x05/[ENQ]/g' -e 's/\x06/[ACK]/g' -e 's/\x07/[BEL]/g' -e 's/\x08/[BS]/g' -e 's/\x0A/[LF]/g' -e 's/\x0B/[VT]/g' -e 's/\x0C/[FF]/g' -e 's/\x0D/[CR]/g' -e 's/\x0E/[SO]/g' -e 's/\x0F/[SI]/g' -e 's/\x10/[DLE]/g' -e 's/\x11/[DC1]/g' -e 's/\x12/[DC2]/g' -e 's/\x13/[DC3]/g' -e 's/\x14/[DC4]/g' -e 's/\x15/[NAK]/g' -e 's/\x16/[SYN]/g' -e 's/\x17/[ETB]/g' -e 's/\x18/[CAN]/g' -e 's/\x19/[EM]/g' -e 's/\x1A/[SUB]/g' -e 's/\x1B/[ESC]/g' -e 's/\x1C/[FS]/g' -e 's/\x1D/[GS]/g' -e 's/\x1E/[RS]/g' -e 's/\x1F/[US]/g' -e 's/\x7F/[DEL]/g'| |
认真去看的话,要提取的字符串前后都有乱七八糟的 ansi 字符和搭配生效的 ansi 命令:
1 | ^[[?25l^[[?1c^[[H^[[J^[[m^Otop - 02:37:10 up 132 days, 19:05, 1 user, load average: 0.00, 0.03, 0.00^[[m^O^[[39;49m^[[m^O^[[39;49m^[[K |
我稍微了解了一下,上面这些 ansi 命令的意思:
1 | ^[[?25l光标不可见 |
其中其决定作用的自然是那个^[[H和^[[J了,就是这两个联合起来才让 top 命令达成了清屏的效果。现在就把他们都干掉!前面,用长长的那一串语句做转换后,要提取的字符串前后的 ansi 字符组变成了下面这样的两串东西:
1 | [ESC][?25l[ESC][?1c[ESC][H[ESC][J[ESC][m[SI] |
复制到 vscode 后,按 ctrl+H,vscode 就能自动的把这两串东西转义成正则表达式形式,真方便。整理一下,放到上面用过的表达式中做处理:
1 | top -n1|sed -n '1p'|sed 's/top - //g'|sed -r -e 's/\x00/[NUL]/g' -e 's/\x01/[SOH]/g' -e 's/\x02/[STX]/g' -e 's/\x03/[ETX]/g' -e 's/\x04/[EOT]/g' -e 's/\x05/[ENQ]/g' -e 's/\x06/[ACK]/g' -e 's/\x07/[BEL]/g' -e 's/\x08/[BS]/g' -e 's/\x0A/[LF]/g' -e 's/\x0B/[VT]/g' -e 's/\x0C/[FF]/g' -e 's/\x0D/[CR]/g' -e 's/\x0E/[SO]/g' -e 's/\x0F/[SI]/g' -e 's/\x10/[DLE]/g' -e 's/\x11/[DC1]/g' -e 's/\x12/[DC2]/g' -e 's/\x13/[DC3]/g' -e 's/\x14/[DC4]/g' -e 's/\x15/[NAK]/g' -e 's/\x16/[SYN]/g' -e 's/\x17/[ETB]/g' -e 's/\x18/[CAN]/g' -e 's/\x19/[EM]/g' -e 's/\x1A/[SUB]/g' -e 's/\x1B/[ESC]/g' -e 's/\x1C/[FS]/g' -e 's/\x1D/[GS]/g' -e 's/\x1E/[RS]/g' -e 's/\x1F/[US]/g' -e 's/\x7F/[DEL]/g'|sed -r -e 's/\[ESC\]\[\?25l\[ESC\]\[\?1c\[ESC\]\[H\[ESC\]\[J\[ESC\]\[m\[SI\]//g' -e 's/\[ESC\]\[m\[SI\]\[ESC\]\[39;49m\[ESC\]\[m\[[SI\]\[ESC\]\[39;49m\[ESC\]\[K//g' |
这样出来的结果就不会有问题了。。。
但是,但是!用 paste 去把这个语句和上面测量 cpu 占用率的两个语句组起来,就会莫名其妙的卡住,原因不明。。。
但解决方法也很简单,这时我才发现 top 里有个参数叫 -b,可以自动把这些 ansi 字符干掉。。。
所以我绕了一大圈是为了什么呢?????
1 | paste <(top -b -n1|sed -n '3p'|awk '{print $2}'|sed 's/us//g') <(top -b -n1|sed -n '1p'|sed 's/top - //g') |